Scaling Neural Face Synthesis to High FPS and Low Latency by Neural Caching
WACV 2023
- Frank Yu University of British Columbia
- Sid Fels University of British Columbia
- Helge Rhodin University of British Columbia
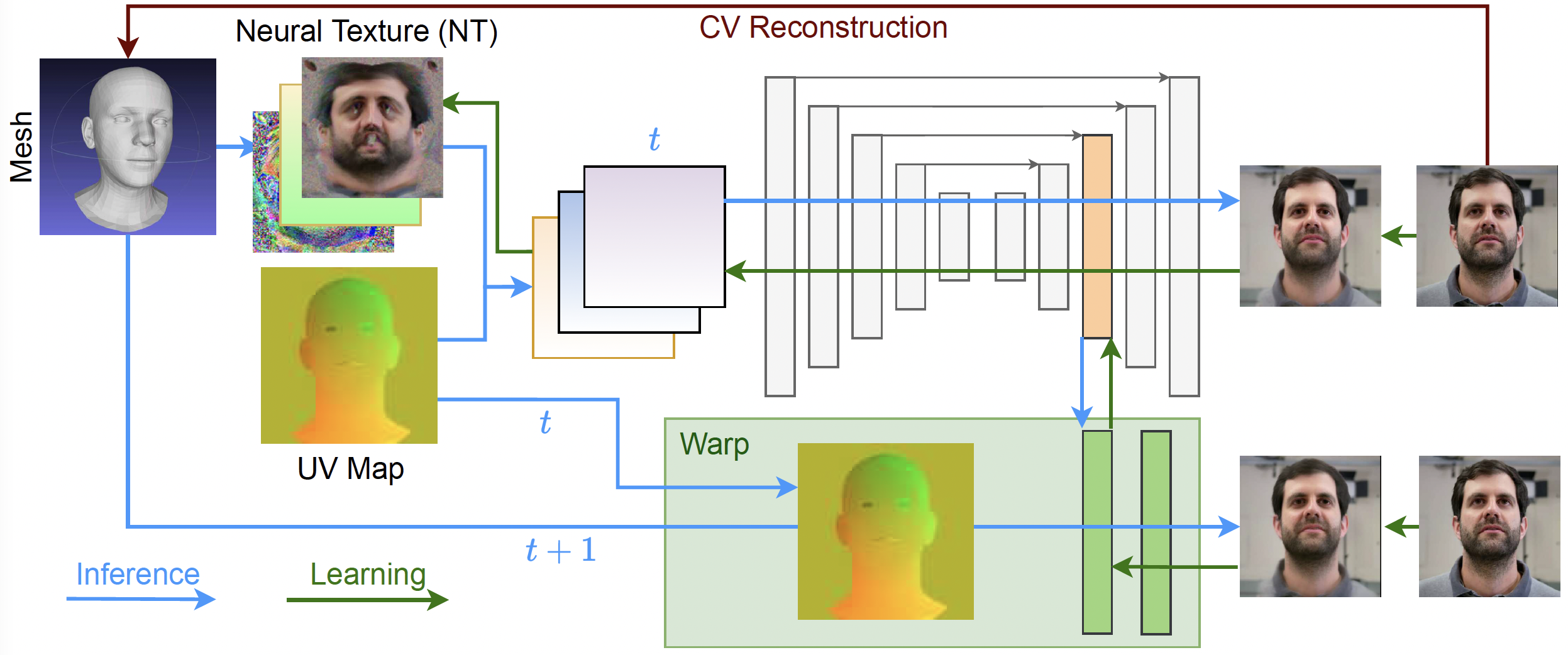
Model training/inference pipeline
Abstract
Recent neural rendering approaches greatly improve image quality, reaching near photorealism. However, the underlying neural networks have high runtime, precluding telepresence and virtual reality applications that require high resolution at low latency. The sequential dependency of layers in deep networks makes their optimization difficult. We break this dependency by caching information from the previous frame to speed up the processing of the current one with an implicit warp. The warping with a shallow network reduces latency and the caching operations can further be parallelized to improve the frame rate. In contrast to existing temporal neural networks, ours is tailored for the task of rendering novel views of faces by conditioning on the change of the underlying surface mesh. We test the approach on view-dependent rendering of 3D portrait avatars, as needed for telepresence, on established benchmark sequences. Warping reduces latency by 70% (from 49.4ms to 14.9ms on commodity GPUs) and scales frame rates accordingly over multiple GPUs while reducing image quality by only 1%, making it suitable as part of end-to-end view-dependent 3D teleconferencing applications.
Citation
The website template was borrowed from Jon Barron.